Quick Follow-up on Inter-node RL Weight Transfer
In the previous blog post, I walked through how we achieved cross-machine RL weight updates in just 2 seconds. This post is a quick follow-up with a few extra details:
- For Kimi-K2 (1T params), with 256 GPUs in BF16 training and 128 GPUs in FP8 inference, weight updates take less than 1.3 seconds.
- The pipeline for parameter updates has been tuned a bit more, adding two parallelizable steps: H2D memcpy and a global communication barrier.
- I ran a PyTorch Profiler trace to get a visual breakdown of the update pipeline and see exactly where time is being spent.
- Added a few figures for easier intuition.
Pipeline Optimization
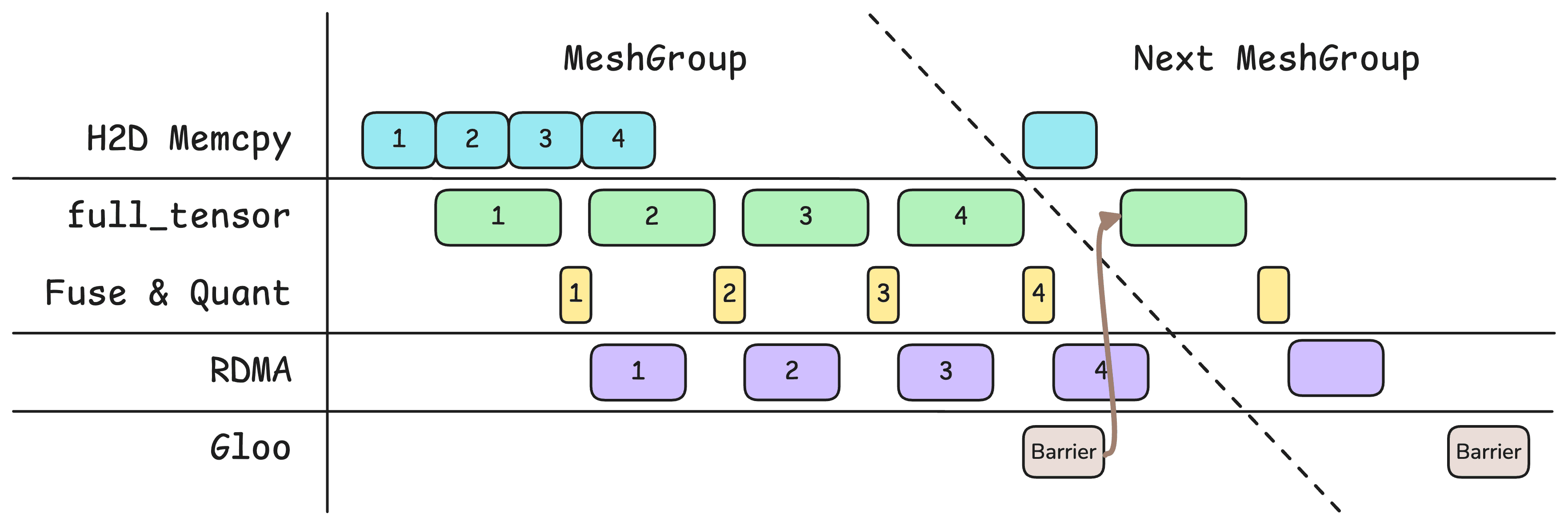
The earlier version only had two pipeline stages: GPU and network. Now there are four:
- H2D memcpy
- GPU ops:
full_tensor(), projection fusion, quantization - RDMA transfer
- Global communication barrier: added right after the last
full_tensor()in each Mesh Group, withasync_op=True. No need to wait for RDMA to finish. Since Gloo runs over Ethernet, this overlaps nicely with RDMA.
PyTorch Profiler
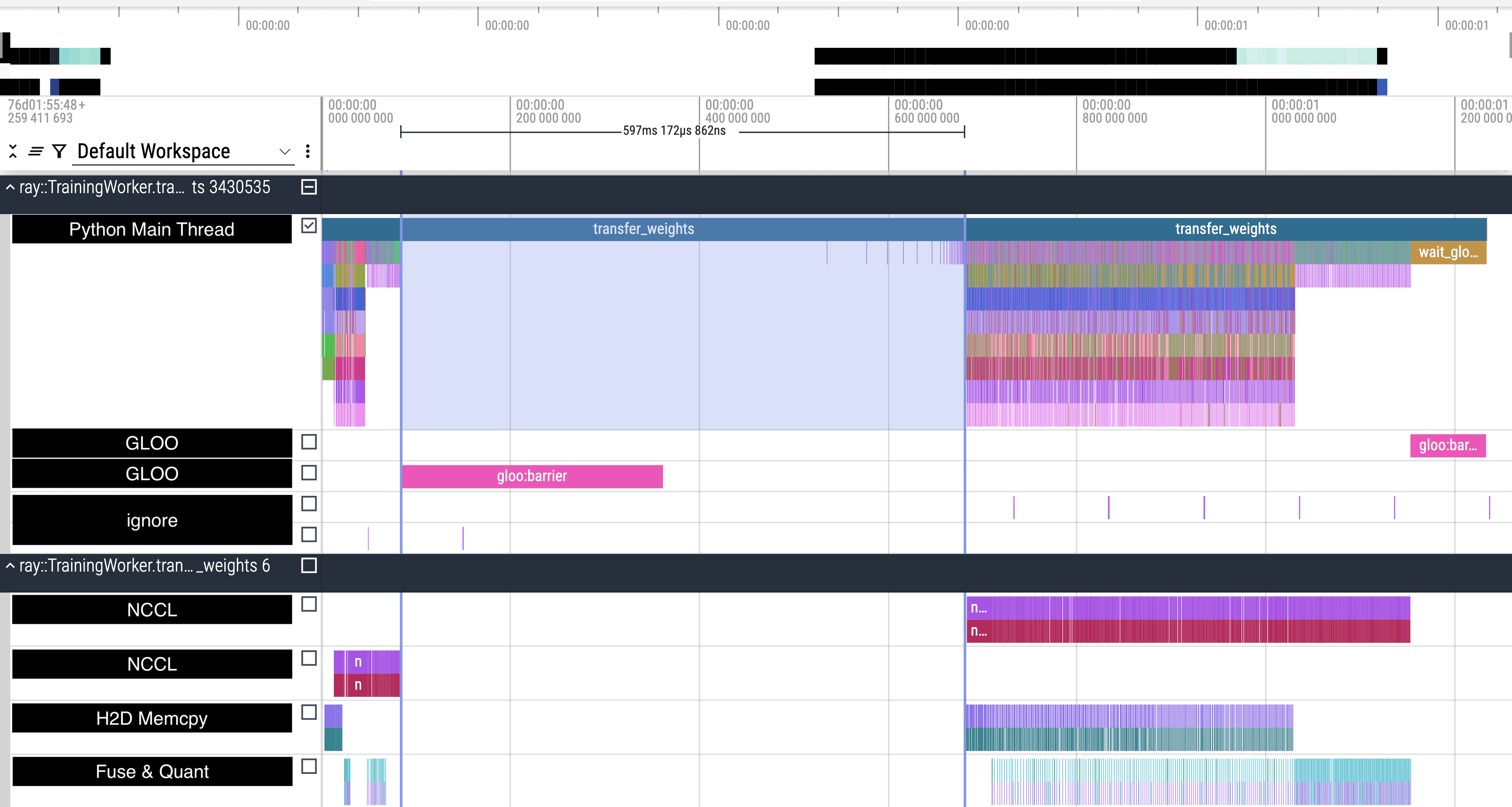
Let’s first look at a full parameter update. From the timeline above, the total time is a bit over 1.2 seconds.
The update is split into two Mesh Groups, separated by a global barrier. The first covers non-MoE parameters, where FSDP shards along the intra-node NVLink dimension. The second covers MoE parameters, where FSDP shards across nodes along the RDMA dimension.
- For non-MoE params,
full_tensor()(basically NCCL all-gather) is very fast since it runs over NVLink. Overall, the bottleneck is RDMA transfer. The global barrier is nicely hidden under RDMA. - For MoE params,
full_tensor()is visibly slower. The global barrier can’t be fully hidden, meaning RDMA finishes earlier than the barrier—likely waiting on some especially slow rank.
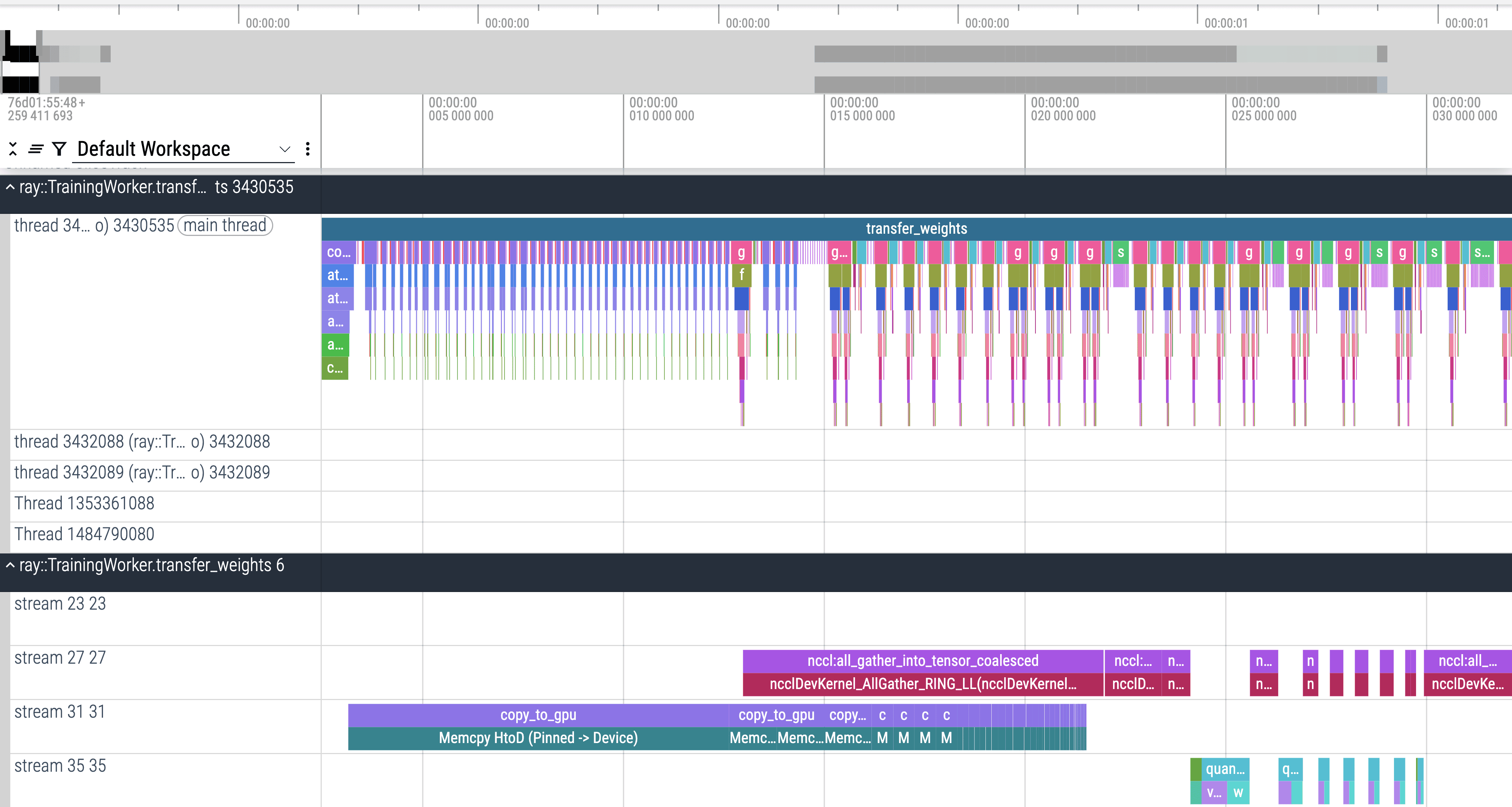
Zoomed in on non-MoE transfers.
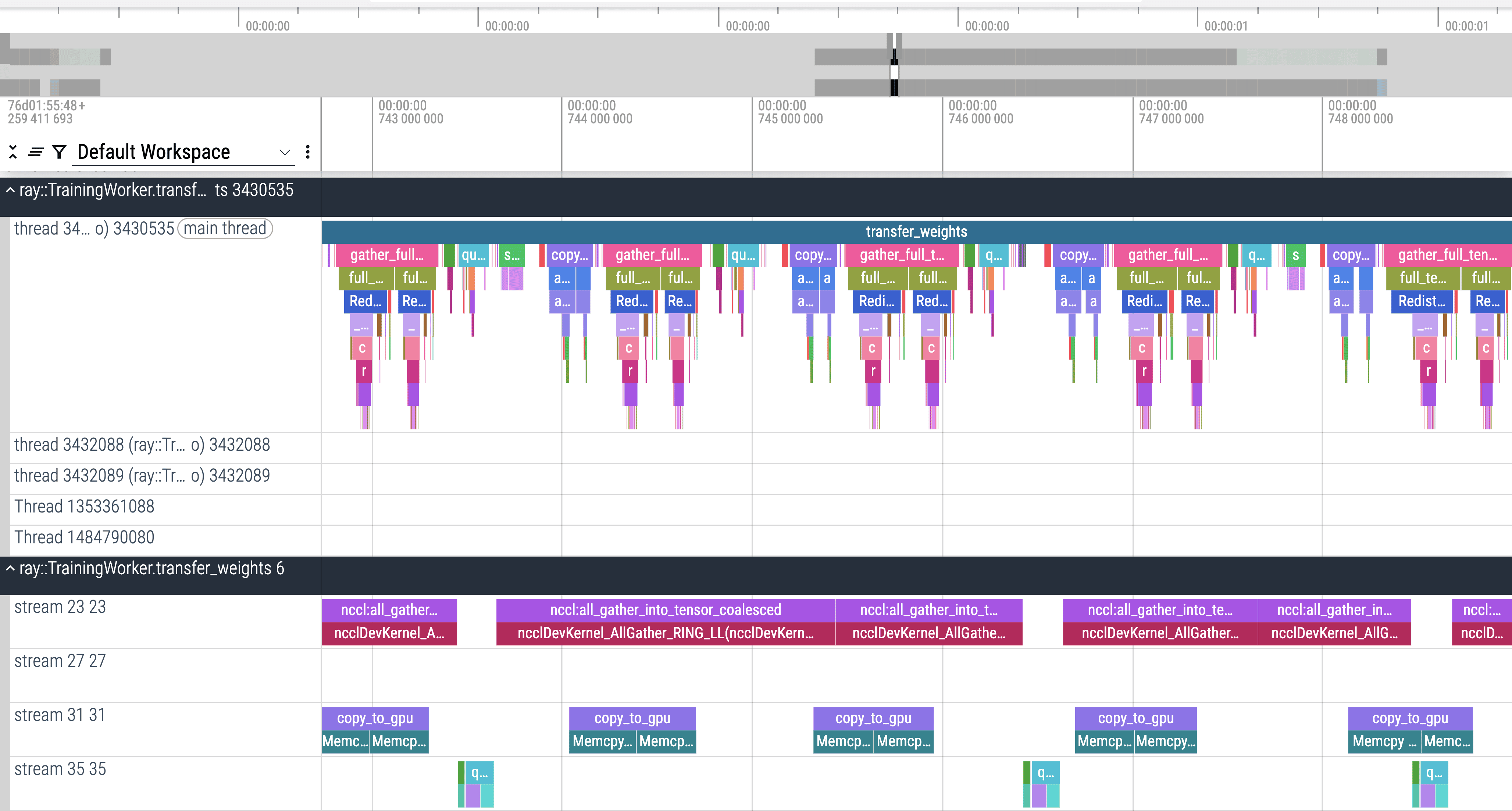
Zoomed in on MoE transfers.
One clear difference:
- For non-MoE params, H2D memcpy finishes in one shot.
- For MoE params, H2D memcpy is interleaved across the entire timeline.
This suggests MoE parameter transfers don’t all launch at once, but rather start gradually as earlier tasks complete. Likely they’re being throttled by the temporary memory cap I had set earlier.
Extra Figures
Rank0-Based vs P2P Weight Updates

Torch.Distributed + RPC vs RDMA Weight Updates
