Journey to 2-second Inter-node RL Weight Transfer
I just spent the past two weeks getting cross-machine parameter updates for Qwen3-235B (BF16 training, FP8 inference) to run in just 2 seconds (128 GPUs for training, 32 GPUs for inference). Instead of writing a “here’s the solution” kind of post, I want to share my exploration process and thoughts along the way. I’ll post a shorter, polished version on the company blog in a few days.
Why Bother
In a previous blog post we mentioned that we built our own in-house LLM inference engine. Also, everyone knows that while we don’t do pretraining, we do put a lot of effort into post-training. So hooking up our inference engine with our post-training framework was the natural next step. And the very first hurdle: updating weights from the training nodes to the inference nodes.
Since we use asynchronous RL training, training and inference run on different machines. That actually makes my life easier here: I don’t even need to unload weights from the inference engine with cuMem or anything — just beam the weights directly from training machines to inference machines. Done.
When a coworker told me some open-source RL frameworks take minutes to update parameters, I was honestly a bit shocked. Take DeepSeek 671B as a back-of-the-envelope example: suppose we shard the weights across 8 GPUs, each with a 400 Gbps (≈50 GB/s) link. Shipping all the weights out would be 671 GB / (8 * 50 GB/s) = 1.68 seconds. Sure, the network won’t actually hit peak, and the receiver might involve multiple machines, but on the flip side you might have more shards, or more training nodes than inference nodes. After all the pluses and minuses cancel out, my gut feeling was the update should be ~1 second. No way it should be in the minutes range.
But hey, whether existing solutions are fast or slow isn’t really my problem. My job was just to hook up our inference engine. I also had zero prior experience with the training side (I can already imagine readers screaming: “Bro, you didn’t know that?!”). So instead of studying existing solutions, I just dove straight in.
The “Obvious” Plan
If you’ve read my RDMA tutorial or the other two posts here, you might recall I hand-rolled an RDMA comms library. So in my head, shipping weights should be about as simple as putting an elephant into a fridge:
- Controller node gathers weight metadata from each training GPU and each inference GPU.
- Controller matches weights by name.
- Controller computes a fixed routing table: which training GPU sends which weights to which inference GPU.
- Controller distributes the routing table to all training GPUs.
- When it’s time to update weights, controller just says: “Alright folks, go!”
- Each training GPU RDMA-writes the right weights to the right inference GPUs according to the routing table.
- Inference GPUs don’t even realize their weights just got swapped under the hood.
This way, we don’t even need to modify our inference engine. Just add some meticulous matching/routing logic on the controller, plus a tiny bit of RDMA code on training workers, and we’re done.
Pseudo-code looks something like this:
@ray.remote
class TrainingWorker:
def get_param_metadata(self) -> dict[str, ParamMeta]: ...
def set_routing_table(self, routing_table: RoutingTable) -> None: ...
def transfer_weights(self) -> None:
for entry in self.routing_table:
src_mr = get_mr(entry.src_ptr)
submit_rdma_write(src_mr, *entry)
wait_for_rdma_writes_to_complete()
@ray.remote
class RolloutWorker:
def get_param_metadata(self) -> dict[str, ParamMeta]: ...
def get_memory_regions(self) -> list[MemoryRegion]: ...
@dataclass
class WeightTransferEntry:
src_ptr: int
src_size: int
dst_ptr: int
dst_size: int
dst_mr: MemoryRegion
RoutingTable: TypeAlias = list[WeightTransferEntry]
def controller_main() -> None:
trainers: list[TrainingWorker] = ...
rollouts: list[RolloutWorker] = ...
trainer_params = ray.get([x.get_param_metadata.remote() for x in trainers])
rollout_params = ray.get([x.get_param_metadata.remote() for x in rollouts])
rollout_mrs = ray.get([x.get_memory_regions.remote() for x in rollouts])
schedule: list[RoutingTable] = compute_weight_transfer_schedule(trainer_params, rollout_params, rollout_mrs)
ray.get([trainer.set_routing_table.remote(routing_table)
for trainer, routing_table in zip(trainers, schedule)])
while training_not_done:
train()
ray.get([trainer.transfer_weights.remote() for trainer in trainers])
rollout()
RDMA Weight Transfer: Proof of Concept
Since I didn’t know our training stack yet, hadn’t touched Ray, and hadn’t written a slurm script in my life, I decided to keep things simple and first prove our inference engine can accept model weights over RDMA.
Plan: use two GPUs. One runs our inference engine without loading weights. The other loads weights in the exact format our inference engine expects, then ships them over. If the transfer works, the inference engine should generate sane text.
For this PoC, I didn’t need any training code at all, so no need to wade into our training framework. Ray also looked pretty beginner-friendly—throw an @ray.remote here, a ray.get() there—and it runs. And we can skip slurm since it’s just two GPUs; I can spin up a Ray head node on my dev machine.
This made development super fast—I wrapped it up in two days. The only hiccup: four tensors always failed to transfer.
The mysterious failures
First I tried the classic “turn it off and on again”: retry the transfer. No matter how many times I retried—or how long I slept before retrying—no luck. The libfabric error message was also… not super helpful:
Unexpected status returned by responder
I dug into libfabric and rdma-core, but the error seemed to be coming from the lower-level EFA driver. My hunch: maybe my memory region math was off. Usually if the Memory Region (MR) is wrong, libfabric complains about a bad rkey, but here it didn’t.
When in doubt, ask. I pinged the AWS EFA team. Huge shoutout—they responded quickly and agreed the error looked odd, and they also suspected bad MR boundaries.
So I chased that angle. One pattern stood out: the four failing tensors were tiny—each under 1 KB (these were FP8 block-quant inv_scales). I suspected my RDMA library’s sharding logic.
EFA links don’t individually hit 400 Gbps, so AWS stuffs multiple EFA NICs into each GPU host (p5 has 4×100 Gbps, p5en has 2×200 Gbps). My library splits a single RDMA WRITE across all NICs. I also had a small “optimization”: if a shard is smaller than the MTU, later NICs send 0-length WRITEs.
When computing MR offsets, I didn’t special-case 0-length segments. That meant the last 0-length WRITE could land right at the end of the MR. End-offsets are open intervals—so that address isn’t actually valid. Boom.
I fixed the offset calculation to special-case 0-length WRITEs, and the problem disappeared.
The AWS engineers also mentioned that RDMA spec doesn’t require verifying the target MR for a 0-length WRITE, but EFA still did. They’re planning to align with the spec and improve the error message. +1 for the EFA team!
Getting PyTorch memory regions
RDMA folks (or anyone who read my RDMA tutorial) know a “memory region” is just four things: ptr, size, rkey, lkey. With ptr and size we can register the MR in the RDMA lib. But how do we get PyTorch’s allocated regions?
The naive way: for each tensor, use data_ptr() and numel() * element_size(). That registers a ton of tiny MRs—ugly. PyTorch has a caching allocator, so the elegant move is to register the allocator’s blocks as MRs.
I figured I’d need some C++ shim to expose the allocator’s blocks, but I checked the docs first (for once). Turns out PyTorch already has a handy function: torch.cuda.memory.memory_snapshot(). It returns all blocks allocated by the CUDACachingAllocator, with their pointers and sizes—perfect for MR registration.
Throughput
I tried transferring the weights for DeepSeek-V2-Lite—about 16 GB—and it took 0.44 s, which is roughly 36 GB/s. That’s without any warm-up. Pretty solid. The inference engine produced normal outputs afterward, so the transfer was indeed correct.
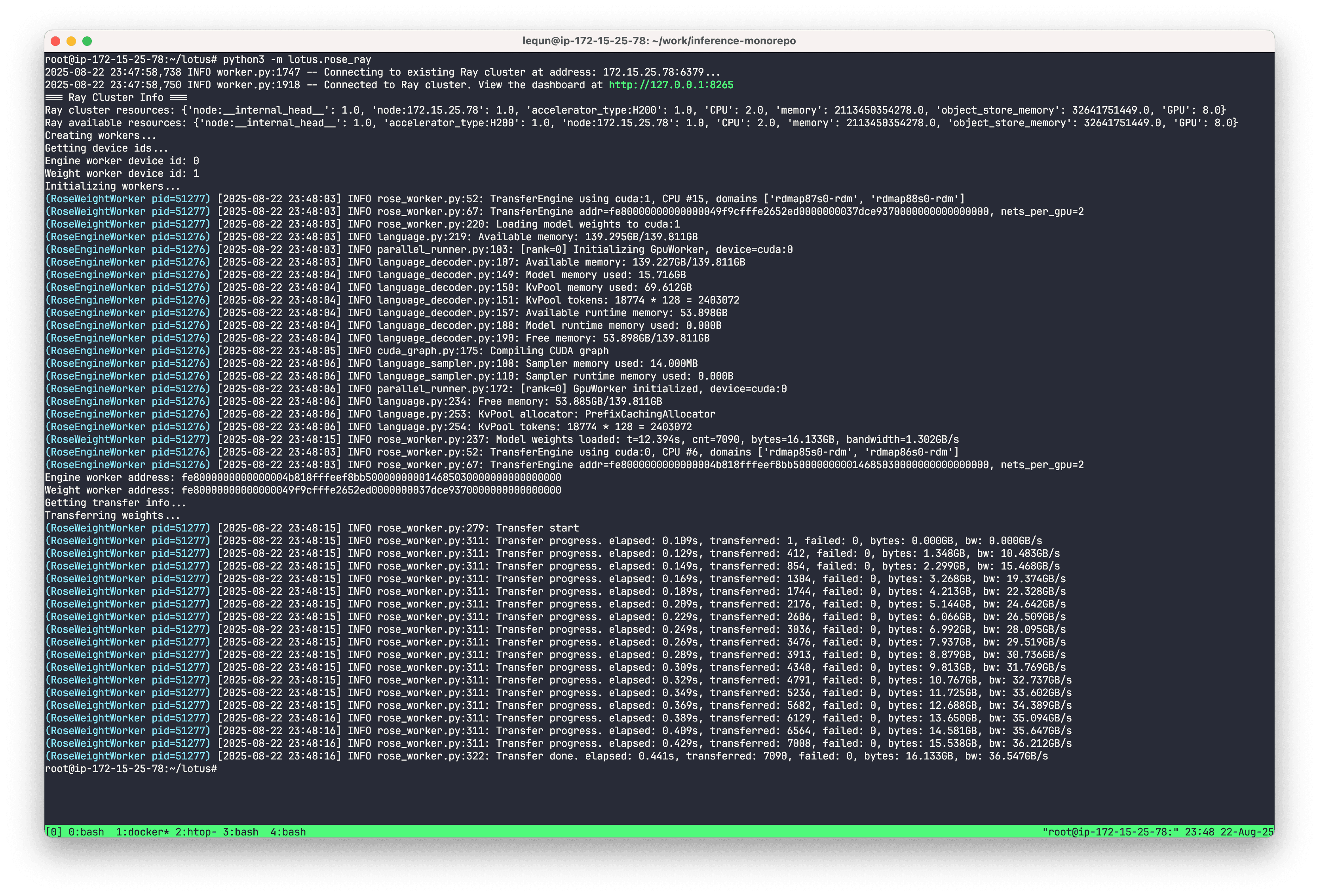
“Real” Weight Updates (first attempt: faceplant)
Buoyed by the PoC, I started implementing the real weight update path. I kept it simple: start with DeepSeek-V2-Lite, no quantization, BF16 for both training and inference. The only extra wrinkle would be projection fusion (e.g., fusing {q,k,v}_proj into qkv_proj). Since fusions are concatenations along dim0, and PyTorch is row-major, I just needed to add an offset during transfer. Easy.
I wrote the name mapping and routing computation, and it worked fine when the training side used one GPU. I assumed scaling that to 8 GPUs or multiple nodes would be straightforward. Next step would be adding quantization.
Reality had other plans. The moment training used more than one GPU, everything fell apart—even the shapes didn’t match.
The shape differences were consistently by a factor of 8. That’s when it hit me: I’d assumed FSDP was “just DP.” Nope—FSDP actually shards parameters. I skimmed the FSDP tutorial, admired the API, and quietly accepted I had to rewrite my approach.
“Real” Weight Updates (second attempt: rewrite)
After reading up on FSDP, DTensor, and DeviceMesh, I realized the routing calculation must respect DTensor Placements. There are two types (we don’t see Partial): Replicate and Shard(dim). Our training configs shard at most one dimension, which keeps complexity manageable.
So the outer architecture stays: compute a routing plan, then do RDMA WRITEs. But the splitting must follow the DTensor placements.
DTensor
If I manually do the splits, I’ll also need to hand-compute offsets for projection fusions. That’s annoying. Quantization is even worse: if a shard size isn’t divisible by the block size, I’d need second-order boundary logic. Plus, FSDP can offload params to CPU, which means manual CPU→GPU moves.
So I decided to follow DTensor’s logic. It won’t be the absolute fastest, but it’s way easier to implement. After calling full_tensor(), every GPU in the DeviceMesh has the full parameter. Then I can do projection fusion and quantization easily, and pick any GPU as the source to send weights to inference.
DeviceMesh
Note that full_tensor() is a collective (for sharded placements, it’s an all-gather), so all GPUs in the same DeviceMesh must call it in the same order. Different DeviceMeshes don’t need to coordinate.
Naturally, the next question: how many DeviceMeshes are there, and can they run in parallel?
This one’s simple. Consider three axes: FSDP, PP, and EP. Suppose we have 32 GPUs total with FSDP=2, PP=2, EP=8. Ignore PP—it doesn’t shard params. For non-MoE params (e.g., {q,k,v}_proj), our training setup shards along EP and replicates along FSDP. That gives a DeviceMesh of 2 * 8 = 16 GPUs, and the 32-GPU cluster splits into two disjoint DeviceMeshes, i.e., one DeviceMesh Group:
Non-MoE DeviceMesh Group:
DeviceMesh 0: 0~7 , 16~23
DeviceMesh 1: 8~15, 24~31
For MoE params, we shard along FSDP, so each DeviceMesh has just 2 GPUs, giving 16 disjoint DeviceMeshes:
MoE DeviceMesh Group:
DeviceMesh 0: 0, 16
DeviceMesh 1: 1, 17
...
DeviceMesh 15: 15, 31
DeviceMeshes within the same group are disjoint, so they can communicate in parallel. We split the overall transfer into phases by DeviceMesh Group and put a global barrier between groups.
Finding these groups is easy—any greedy partitioner will do:
def find_disjoint_mesh_groups(mesh_set: set[Mesh]) -> list[set[Mesh]]:
"""Example:
Input: {
Mesh([range(0, 8), range(16, 24)]),
Mesh([range(8, 16), range(24, 32)]),
Mesh([0, 16]),
Mesh([1, 17]),
...
Mesh([15, 31]),
}
Output: [
{
Mesh([range(0, 8), range(16, 24)]),
Mesh([range(8, 16), range(24, 32)]),
},
{
Mesh([0, 16]),
Mesh([1, 17]),
...
Mesh([15, 31]),
},
]
"""
Matching training & inference parameters
Name matching is a fussy job. You can hardcode patterns by eyeballing, but I wanted something cleaner—think compiler passes. Step by step, we normalize, check, and compute a routing plan.
To handle quant scales and bundle them with the weights, I introduced two types:
@dataclass(slots=True, frozen=True)
class Identity:
base_name: str
@property
def weight_name(self) -> str:
return self.base_name + ".weight"
@dataclass(slots=True, frozen=True)
class Quantization:
base_name: str
scale_suffix: str
@property
def weight_name(self) -> str:
return self.base_name + ".weight"
@property
def scale_name(self) -> str:
return self.base_name + self.scale_suffix
Then we can normalize raw names into one of these:
def group_quant_weight_names(
scale_suffix: str,
weight_names: set[str],
) -> list[Identity | Quantization]:
"""
For example,
- ["foo.weight", "foo.weight_inv_scale"] -> [Quantization("foo", ".weight_inv_scale")]
- ["bar.weight"] -> [Identity("bar")]
"""
On the training side we must also handle renames and projection fusion. Since rules differ per model, each model provides a function that maps inference names to training names. On the training side, we add a third type, ProjectionFusion, to represent fused projections:
@dataclass(slots=True, frozen=True)
class ProjectionFusion:
weight_names: tuple[Identity, ...] | tuple[Quantization, ...]
class ModelWeightMatcher(Protocol):
def map_trainer_weight_name(
self,
trainer_quant_weight_names: list[Identity | Quantization],
) -> dict[str, Identity | Quantization | ProjectionFusion]:
"""
For example:
Input: [
Quantization("layers.0.attn.q_proj", ".weight_inv_scale"),
Quantization("layers.0.attn.k_proj", ".weight_inv_scale"),
Quantization("layers.0.attn.v_proj", ".weight_inv_scale"),
Identity("layers.0.mlp.down_proj"),
]
Output: {
"layers.0.attn.qkv_proj": ProjectionFusion(
weight_names=(
Quantization("layers.0.attn.q_proj", ".weight_inv_scale"),
Quantization("layers.0.attn.k_proj", ".weight_inv_scale"),
Quantization("layers.0.attn.v_proj", ".weight_inv_scale"),
)
),
"layers.0.mlp.down_proj": Identity("layers.0.mlp.down_proj"),
}
"""
With that, the actual matching becomes a sequence of tidy checks:
@dataclass(slots=True, frozen=True)
class WeightNameMapping:
trainer: Identity | Quantization | ProjectionFusion
rollout: Identity | Quantization
do_quant: bool
def match_weight_names(
trainer_named_parameters: dict[str, ParamMeta],
rollout_named_parameters: dict[str, ParamMeta],
matcher: ModelWeightMatcher,
) -> list[WeightNameMapping]:
trainer_quant_weight_names = group_quant_weight_names(trainer_named_parameters)
rollout_naming_map = {x.weight_name: x for x in group_quant_weight_names(rollout_named_parameters)}
trainer_weight_name_map = matcher.map_trainer_weight_name(trainer_quant_weight_names)
for expected_rollout_weight_name, trainer_naming in trainer_weight_name_map.items():
rollout_naming = rollout_naming_map[expected_rollout_weight_name]
# Expand shape by mesh placement
# Check shape, dtype, duplicate, etc...
Building the routing table
The goal is a per-training-GPU plan: in what order to send which weights to which inference GPUs.
@dataclass(slots=True)
class WeightTransferEntry:
name_mapping: WeightNameMapping
rollout_workers: tuple[int, ...]
@dataclass(slots=True)
class WeightTransferGroup:
mesh_group: set[Mesh]
transfer_entries: list[WeightTransferEntry]
@dataclass(slots=True)
class WeightTransferRoutingTable:
groups: list[WeightTransferGroup]
@dataclass(slots=True)
class WeightTransferSchedule:
trainers: list[WeightTransferRoutingTable]
def generate_table_for_mesh_group(
trainers: list[ParametersMetadata],
rollouts: list[ParametersMetadata],
name_mappings_with_mesh: list[tuple[WeightNameMapping, Mesh]],
mesh_group: set[Mesh],
) -> list[WeightTransferGroup]:
transfer_entries_list: list[list[WeightTransferEntry]] = [[] for _ in trainers]
send_bytes = [0] * len(trainers)
for name_mapping, mesh in name_mappings_with_mesh:
owners = mesh.members()
for i_rollout, rollout in enumerate(rollouts):
winner = ... # min owner by send_bytes
# Assign winner to i_rollout
for owner in owners:
transfer_entries_list[owner].append(...)
def compute_weight_transfer_schedule(
trainers: list[ParametersMetadata],
rollouts: list[ParametersMetadata],
trainer_named_parameters: dict[str, ParameterMetadata],
name_mappings: list[WeightNameMapping],
) -> WeightTransferSchedule:
mesh_set: set[Mesh] = ...
mesh_groups = find_disjoint_mesh_groups(mesh_set)
trainer_tables = [WeightTransferRoutingTable([]) for _ in trainers]
for mesh_group in mesh_groups:
trainer_groups = generate_table_for_mesh_group(trainers, rollouts, name_mappings_with_mesh, mesh_group)
for table, group in zip(trainer_tables, trainer_groups):
table.groups.append(group)
return WeightTransferSchedule(trainer_tables)
Two reminders, since full_tensor() is a collective:
- All GPUs in a DeviceMesh must call
full_tensor()in the same order. Even if a particular rank doesn’t need to send anything for the current tensor, it still must callfull_tensor(). - Insert a global
torch.distributed.barrier()between DeviceMesh Groups. So the routing table needs to reflect group boundaries.
For load-balancing sources after full_tensor(): RDMA bandwidth between any pair of GPUs is the same, so I just track bytes sent per training GPU. For each parameter and each inference target, pick the training GPU with the smallest current byte count. It’s not optimal, but it’s simple and good enough.
Executing the transfer
The training-side logic involves both GPU work (CPU→GPU moves, full_tensor(), projection fusion, quantization) and network work (RDMA). I want those to overlap. I also want to (roughly) cap peak VRAM usage during the process.
My approach is to give each transfer task a small state machine:
@dataclass(slots=True)
class _WeightTransferTask:
spec: WeightTransferEntry
num_transfers: int
total_bytes: int
# Step 1: Gather full_tensor() (async GPU operations)
weight_full_tensors: list[torch.Tensor] | None = None
scale_full_tensors: list[torch.Tensor] | None = None
# Step 2: Transform tensors (async GPU operations)
# Step 2a: Fuse projection
# Step 2b: Quantize on-the-fly
weight_tensor: torch.Tensor | None = None
scale_tensor: torch.Tensor | None = None
# Step 3: Wait for async GPU operations to finish
gpu_op_done: torch.cuda.Event | None = None
# Step 4: Submit RDMA transfers
submitted_transfer: bool = False
# Step 5: Wait for transfers to finish
finished_transfers: int = 0
def is_done(self) -> bool:
return self.submitted_transfer and self.finished_transfers == self.num_transfers
And bucket tasks into three queues:
- Not started
- Waiting for GPU ops to finish
- Waiting for RDMA to finish
class transfer_weights:
def __init__(
self,
fabric: TransferEngine,
model: nn.Module,
transfer_entries: list[WeightTransferEntry],
max_tmp_bytes: int = 1<<30,
) -> None:
self.tmp_bytes = 0
self.rdma_done_queue: Queue[_WeightTransferTask] = Queue()
tasks: deque[_WeightTransferTask] = deque()
for entry in transfer_entries:
tasks.append(_WeightTransferTask(...))
self.tasks_not_started = tasks
self.tasks_waiting_gpu_op: deque[_WeightTransferTask] = deque()
self.tasks_waiting_transfer: deque[_WeightTransferTask] = deque()
while self.tasks_not_started or self.tasks_waiting_gpu_op or self.tasks_waiting_transfer:
self._poll_progress()
Each tick, we progress tasks based on state:
class transfer_weights:
...
def _poll_progress(self) -> None:
# Clear finished tasks
while self.tasks_waiting_transfer:
task = self.tasks_waiting_transfer[0]
if not task.is_done():
break
task = self.tasks_waiting_transfer.popleft()
self.tmp_bytes -= task.total_bytes
# Kick off async GPU operations
while self.tasks_not_started:
task = self.tasks_not_started[0]
if self.tmp_bytes + task.total_bytes > self.max_tmp_bytes:
break
task = self.tasks_not_started.popleft()
self.tasks_waiting_gpu_op.append(task)
self.tmp_bytes += task.total_bytes
self._to_device(task) # roughly: .to(device, non_blocking=True)
self._gather_full_tensors(task) # roughly: .full_tensor()
self._fuse_projection(task) # roughly: torch.cat()
self._quantize(task)
task.gpu_op_done = torch.cuda.Event()
task.gpu_op_done.record()
# Wait for async GPU operations to finish and submit transfers
while self.tasks_waiting_gpu_op:
task = self.tasks_waiting_gpu_op[0]
assert task.gpu_op_done is not None
if not task.gpu_op_done.query():
break
task = self.tasks_waiting_gpu_op.popleft()
self.tasks_waiting_transfer.append(task)
self.fabric.submit_write(
...,
callback=(lambda task: lambda: self.rdma_done_queue.put(task))(task),
)
task.submitted_transfer = True
# Handle completed transfer
while True:
try:
task = self.queue.get_nowait()
except Empty:
break
task.finished_transfers += 1
Sharp-eyed readers probably noticed: those GPU calls look blocking, but in practice they’re not. I briefly tried async_op=True on .full_tensor() and used AsyncCollectiveTensor.completed to check progress—but I got wrong results unless I sprinkled in a time.sleep(0.01). After reading the PyTorch Distributed docs on asynchronous semantics, I realized completed only means “submitted to the CUDA stream,” not “finished.”
And most PyTorch ops just enqueue kernels on a CUDA stream. Unless we explicitly sync, the Python thread won’t block. So using async_op=True here was me over-engineering it.
How do we know when GPU work is truly done without blocking? Classic trick: after enqueuing the ops, insert a CUDA event and later call event.query() to check completion. Once it’s done, submit the RDMA.
Also, remember the global barrier between DeviceMesh Groups:
@ray.remote
class TrainingWorker:
def set_routing_table(self, routing_table: WeightTransferRoutingTable) -> None: ...
def transfer_weights(self) -> None:
for group in self._routing_table.groups:
transfer_weights(..., group.transfer_entries)
torch.distributed.barrier()
That’s the whole implementation.
Qwen3-235B FP8 in ~2 seconds
After some light debugging, the new code sailed through DeepSeek-V2-Lite (BF16 train / BF16 infer). Then I turned on FP8 block quant—still instant. For Qwen3-235B (BF16 train / FP8 infer), I tweaked the projection fusion rules a bit and it ran smoothly on 128 training GPUs, 32 inference GPUs.
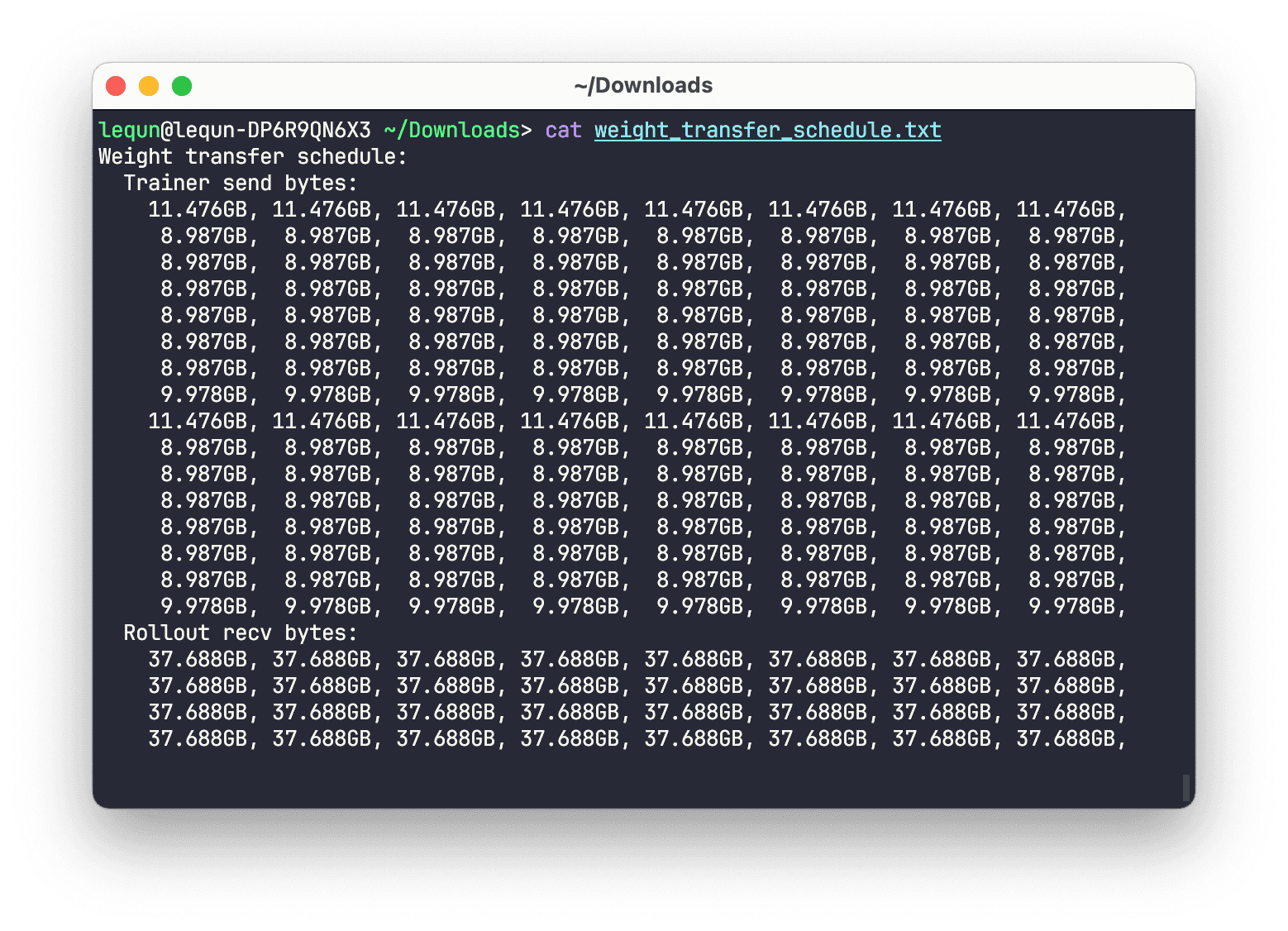
You can see per-training-GPU send bytes and per-inference-GPU receive bytes from the routing plan. It’s not perfectly balanced, but it’s fine.
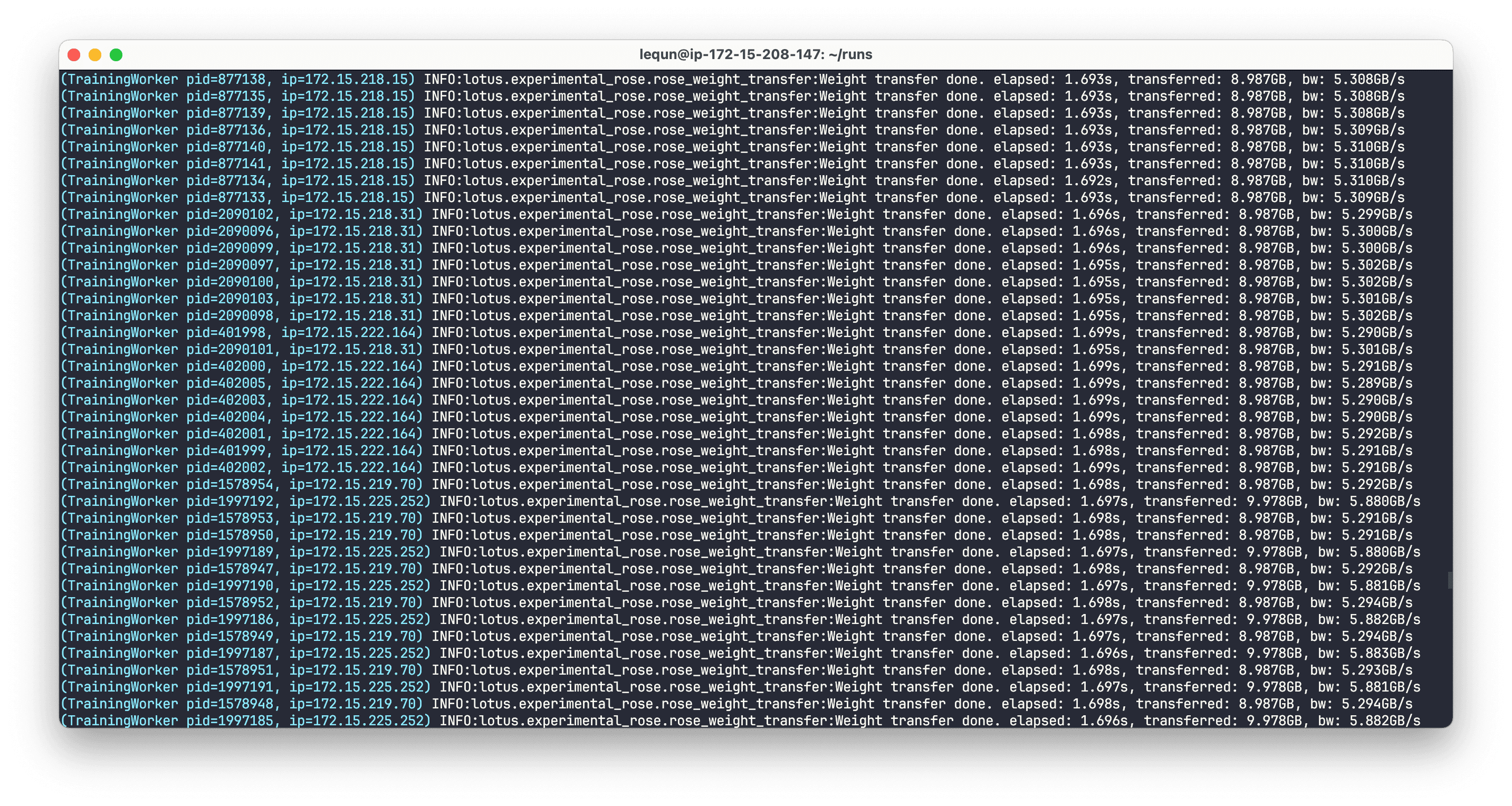
That chart shows a full transfer finishing with a nice snap in under 2 seconds. The effective bandwidth is only about 5 GB/s—a far cry from the theoretical 50 GB/s and the 36 GB/s from the PoC—but given all the GPU work we’re doing in the loop, it’s understandable.
Why not saturate bandwidth?
I’m not rushing to optimize yet, but I did want to know where the time goes. I sprinkled in more CUDA events and computed timings.
Eyeballing the numbers, most of the time goes into submitting GPU ops and waiting for them to finish. I’ll clean up the measurements later and post a small analysis.
Why existing frameworks might be slower
(Important disclaimer: this isn’t a dunk on anyone. I’m just an outsider guessing why some frameworks struggle here. If I’m off, feel free to correct me. Also, our inference and post-training stacks are intentionally minimal and tailored to a few specific scenarios—not a combinatorial explosion of features. That makes engineering and optimization way easier. Comparing a lean internal setup to mature, general frameworks isn’t exactly fair. Huge respect for folks doing the hard work in open source.)
Quick drive-by research
I’m not super familiar with RL infra, so I don’t have a great feel for typical update times. A recent post from two weeks ago shared these numbers:
~7 s to sync BF16 weights for Qwen3 30B-A3B in a train-and-serve setup, and ~100 s for GLM4.5 355B-A32B with FP8 blockwise quant + update.
(UPDATE: 2025-09-08 @Zilin Zhu provided updated data)
In a training-inference distributed setup (64 training GPUs, 64 inference GPUs), Qwen3 235B-A22B weight transfer from BF16 training to FP8 inference takes about 8s.
There’s also a NeMo-RL blog from last month about weight-update optimization, and Chayenne Zhao has a nice summary of mainstream approaches:
update_weights_from_disk: write to disk then read, simple/transparent, performance depends on storage.update_weights_from_distributed: gather to training rank-0, send to inference rank-0, then fan-out to other inference ranks.update_weights_from_tensor: like #2 but with train-and-serve specific optimizations (e.g., CUDA IPC handles), at the cost of intrusive changes in the inference engine.
Some guesses
Again, I haven’t benchmarked these frameworks or combed their code, so take this as educated speculation:
- Rank-0 bottleneck between training↔inference. If all inter-node traffic goes through a single GPU, you’re capped by that GPU’s PCIe bandwidth and its single NIC link (e.g., 400 Gbps = 50 GB/s), not the aggregate of all GPUs/NICs.
- RPC overhead. If every tensor update triggers an RPC into the inference process, control-plane chatter (likely over TCP) and ser/de can add up.
- Not enough overlap/pipelining. Each tensor update can be staged across different resources: GPU ops vs RDMA. If you send layer-by-layer or tensor-by-tensor without overlapping, you leave performance on the floor—sometimes to avoid running out of VRAM.
- Repeated plan computation & retransmission of transfer schemes.
- Tightly coupled implementation (name matching, routing, fusion, quantization, intra-node copies, inter-node transfers, mem limits) making it hard to reason about and optimize.
My approach is more like: open the fridge, put the elephant in, close the door. Because:
- Every training GPU can send; every inference GPU can receive. You actually use all the RDMA bandwidth.
- The inference engine stays unmodified—no control-plane RPCs. Inference GPU doesn’t even know its weights got swapped.
- Each tensor’s transfer has three stages—enqueue GPU ops, wait for GPU ops & submit RDMA, wait for RDMA. As soon as one stage finishes, move to the next. As soon as resources free up, start the next tensor.
- Compute the transfer plan once at startup on the controller, push it down to training workers, then just execute it on each update.
- Both plan computation and execution are split into clean phases—easy to implement, easy to unit test.
So why don’t frameworks just use RDMA point-to-point? My guess: no convenient API.
Most people reach for torch.distributed, which runs on NCCL. Yes, NCCL and torch.distributed have p2p, but it’s not very flexible:
- Sender
send(tensor)and receiverrecv(tensor)must agree on the exact dtype and shape. - Transfers are blocking—
send(t2)waits forsend(t1)to complete, same forrecv.
Raw RDMA, on the other hand, is both flexible and fast:
- Receiver does nothing. It doesn’t even know its memory changed.
- You can freely choose sizes and destination addresses.
- Transfers are asynchronous—don’t block sender or receiver.
- Data plane stays out of the Linux kernel. User space submits WRITEs directly to the NIC; the NIC DMA-reads from system memory or from GPU memory.
Maybe what you need is… an RDMA library?
After playing with our RDMA library for a while, we realized that with a good RDMA library, a lot of things become straightforward: KV cache transfer, weight updates, and some fun ideas you probably wouldn’t expect. Our library on AWS EFA is getting more stable and faster over time. I’m currently adding support for ConnectX-7. We’ll open-source it soon™—stay tuned.
And if you’re curious about what we’re building, we’re hiring—feel free to send an application via our job board.
Update
2025-09-17: Quick Follow-up on Inter-node RL Weight Transfer