Harnessing 3200Gbps Network (6): GPUDirect RDMA WRITE
In the previous chapter, we implemented bidirectional RECV and SEND, which are two-sided RDMA operations. In this chapter, we will extend the previous program to implement WRITE, which directly writes to remote memory. WRITE is a one-sided RDMA operation (One-sided RDMA) that does not require the participation of the remote CPU. In this chapter, we will directly write to GPU memory. From the perspective of the libfabric API, writing to host memory and writing to video memory are the same, so if the reader needs to write to host memory, they only need to convert the GPU memory address to the host memory address. We will name the program for this chapter 6_write.cpp.
Business Logic
Starting from this chapter, we will assume that we are building an application with the following business logic.
Imagine we are storing some values that can be indexed by a page index. A value is divided into N*M parts, distributed across N GPUs, with each GPU having M large buffers. The size of each value in each buffer is the same (Page Size). The client sends a request to the server, asking the server to fill random numbers on specified pages according to a given random seed. The rough business logic is as follows:
def random_fill(seed: int,
num_gpus: int,
buf_addrs: list[int],
page_size: int,
page_indices: list[int]):
bufs_per_gpu = len(buf_addrs) // num_gpus
for gpu_idx in range(num_gpus):
for gpu_buf_idx in range(bufs_per_gpu):
buf_idx = gpu_idx * bufs_per_gpu + gpu_buf_idx
rng = RandomGenerator(seed + buf_idx)
for page_idx in page_indices:
addr = buf_addrs[buf_idx] + page_idx * page_size
rng.fill(addr, page_size)
In this chapter and subsequent chapters, we assume that each GPU has two buffers.
In this chapter, we will focus on learning how to use RDMA WRITE and GPUDirect RDMA (direct data transfer between network cards and GPUs). Therefore, we will only consider 1 GPU and transfer a very small number of pages. In later chapters, we will make the program more robust, able to transfer more pages, and support multiple GPUs and network cards.
GPU Buffers
libfabric supports accessing memory from other devices, a feature called HMEM. For CUDA devices, libfabric has two access methods: through the GDRCopy library and through Linux kernel’s dma-buf. I couldn’t find documentation about these two methods, and could only find snippets from GitHub:
- NCCL defaults to using dma-buf above CUDA 11.7, and uses GDR for software and hardware that don’t support dma-buf [1].
libfabric’s core developer Sean Hefty mentioned that dma-buf is similar to GDR, but uses a more upstream mechanism [2].- The
libfabricefaProvider will prioritize trying dma-buf when detecting CUDA p2p support [3].
From my own experience, I couldn’t discern performance differences between the two. I suspect that for newer software and hardware, dma-buf might be preferred. However, in this article, I’ll write code paths for both methods for the reader’s reference.
In previous articles, we implemented the Buffer class using host memory addresses. To support GPU memory, we’ll add two additional members: cuda_device and dmabuf_fd. We’ll also add a function to allocate space from video memory.
struct Buffer {
void *data;
size_t size;
int cuda_device = -1; // Added
int dmabuf_fd = -1; // Added
bool is_cuda() const { return cuda_device >= 0; }
static Buffer AllocCuda(size_t size, size_t align) {
void *raw_data;
struct cudaPointerAttributes attrs = {};
CUDA_CHECK(cudaMalloc(&raw_data, size));
CUDA_CHECK(cudaPointerGetAttributes(&attrs, raw_data));
CHECK(attrs.type == cudaMemoryTypeDevice);
int cuda_device = attrs.device;
int fd = -1;
CU_CHECK(cuMemGetHandleForAddressRange(
&fd, (CUdeviceptr)align_up(raw_data, align), size,
CU_MEM_RANGE_HANDLE_TYPE_DMA_BUF_FD, 0));
return Buffer(raw_data, size, align, cuda_device, fd);
}
// ...
};
Here we use cudaMalloc() to allocate space from video memory. Then we use cuMemGetHandleForAddressRange() to obtain the dmabuf_fd.
Registering Memory Regions
When registering memory regions, we also need to make some changes:
void Network::RegisterMemory(Buffer &buf) {
struct fid_mr *mr;
struct fi_mr_attr mr_attr = {
.iov_count = 1,
.access = FI_SEND | FI_RECV | FI_REMOTE_WRITE | FI_REMOTE_READ |
FI_WRITE | FI_READ,
};
struct iovec iov = {.iov_base = buf.data, .iov_len = buf.size};
struct fi_mr_dmabuf dmabuf = {
.fd = buf.dmabuf_fd, .offset = 0, .len = buf.size, .base_addr = buf.data};
uint64_t flags = 0;
if (buf.is_cuda()) {
mr_attr.iface = FI_HMEM_CUDA;
mr_attr.device.cuda = buf.cuda_device;
if (buf.dmabuf_fd != -1) {
mr_attr.dmabuf = &dmabuf;
flags = FI_MR_DMABUF;
} else {
mr_attr.mr_iov = &iov;
}
} else {
mr_attr.mr_iov = &iov;
}
FI_CHECK(fi_mr_regattr(domain, &mr_attr, flags, &mr));
this->mr[buf.data] = mr;
}
First, the access. Here we add local and remote one-sided RDMA read and write permissions. Then we set different configurations based on memory type:
- For host memory, we need to use
mr_iov. - For video memory using GDRCopy, we use
mr_iovand setifacetoFI_HMEM_CUDA. - For video memory using dma-buf, we use
dmabufand setifacetoFI_HMEM_CUDA. Becausemr_iovanddmabufare in the sameunion, we need to setflagstoFI_MR_DMABUFto letlibfabricknow we’re usingdmabuf.
WRITE Operations
In previous chapters, we built the RdmaOp class to save the context of RDMA operations, which included RECV and SEND operation types. The WRITE operation is similar to the previous two, and when the operation ends, there will be a corresponding context in the completion queue. Therefore, we need to add a type for saving the WRITE operation context.
On the other hand, because WRITE is a one-sided RDMA operation, the target node does not generate a completion event. The exception is when the WRITE operation carries an immediate data, in which case the target node will generate a completion event. We can use this immediate data as a flag to find the corresponding context. In the fi_info information obtained in the previous chapter, we can see that the EFA supports an immediate data size of 4 bytes.
constexpr size_t kEfaImmDataSize = 4;
enum class RdmaOpType : uint8_t {
kRecv = 0,
kSend = 1,
kWrite = 2, // Added
kRemoteWrite = 3, // Added
};
struct RdmaWriteOp {
Buffer *buf;
size_t offset;
size_t len;
uint32_t imm_data;
uint64_t dest_ptr;
fi_addr_t dest_addr;
uint64_t dest_key;
};
static_assert(std::is_pod_v<RdmaWriteOp>);
struct RdmaRemoteWriteOp {
uint32_t op_id;
};
static_assert(std::is_pod_v<RdmaRemoteWriteOp>);
static_assert(sizeof(RdmaRemoteWriteOp) <= kEfaImmDataSize);
struct RdmaOp {
RdmaOpType type;
union {
RdmaRecvOp recv;
RdmaSendOp send;
RdmaWriteOp write; // Added
RdmaRemoteWriteOp remote_write; // Added
};
std::function<void(Network &, RdmaOp &)> callback;
};
Next, we’ll implement the WRITE operation.
void Network::PostWrite(RdmaWriteOp &&write,
std::function<void(Network &, RdmaOp &)> &&callback) {
auto *op = new RdmaOp{
.type = RdmaOpType::kWrite,
.write = std::move(write),
.callback = std::move(callback),
};
struct iovec iov = {
.iov_base = (uint8_t *)write.buf->data + write.offset,
.iov_len = write.len,
};
struct fi_rma_iov rma_iov = {
.addr = write.dest_ptr,
.len = write.len,
.key = write.dest_key,
};
struct fi_msg_rma msg = {
.msg_iov = &iov,
.desc = &GetMR(*write.buf)->mem_desc,
.iov_count = 1,
.addr = write.dest_addr,
.rma_iov = &rma_iov,
.rma_iov_count = 1,
.context = op,
.data = write.imm_data,
};
uint64_t flags = 0;
if (write.imm_data) {
flags |= FI_REMOTE_CQ_DATA;
}
FI_CHECK(fi_writemsg(ep, &msg, flags)); // TODO: handle EAGAIN
}
Because the WRITE operation has many input parameters, to make the code clearer, we used the RdmaWriteOp structure to save input parameters. Unlike the SEND operation, which only needs to specify the [buf, buf+size) on the send side, the WRITE operation also needs to specify the memory address on the target side. Additionally, to prevent unauthorized remote read and write, RDMA also needs to specify the remote access key for the target memory region. We’ll see how this key is exchanged in the following text.
For WRITE operations with immediate data, we need to set the FI_REMOTE_CQ_DATA flag. This flag will cause the target side to generate a completion event, and we can use this event to find the corresponding context.
Although fi_writemsg() supports multiple sender-side iov and multiple target-side rma_iov, from the fi_info we can see that EFA only supports a single rma_iov. Therefore, if we have multiple non-contiguous memory regions that need to be written, we need to call fi_writemsg() multiple times.
An interesting point is that when registering memory regions, we need to separately set the dma-buf flag. However, in RDMA operations, we don’t need to care about which device the memory region is on, nor how it is accessed.
Remote Write Callback Functions
When a WRITE operation carries an immediate data, the target side will generate a completion event. If the target side expects a WRITE operation with immediate data, we can set up the callback function in advance to be called when the completion event occurs.
struct Network {
// ...
std::unordered_map<uint32_t, RdmaOp *> remote_write_ops;
};
void Network::AddRemoteWrite(
uint32_t id, std::function<void(Network &, RdmaOp &)> &&callback) {
CHECK(remote_write_ops.count(id) == 0);
auto *op = new RdmaOp{
.type = RdmaOpType::kRemoteWrite,
.remote_write = RdmaRemoteWriteOp{.op_id = id},
.callback = std::move(callback),
};
remote_write_ops[id] = op;
}
Handling Completion Events
When handling completion events, we first need to determine if it’s a WRITE operation with immediate data, i.e., FI_REMOTE_WRITE. If so, we need to find the context corresponding to the immediate data cqe.data from remote_write_ops. For other types of operations, the context is cqe.op_context.
void HandleCompletion(Network &net, const struct fi_cq_data_entry &cqe) {
RdmaOp *op = nullptr;
if (cqe.flags & FI_REMOTE_WRITE) {
// REMOTE WRITE does not have op_context
uint32_t op_id = cqe.data;
if (!op_id)
return;
auto it = net.remote_write_ops.find(op_id);
if (it == net.remote_write_ops.end())
return;
op = it->second;
net.remote_write_ops.erase(it);
} else {
// RECV / SEND / WRITE
op = (RdmaOp *)cqe.op_context;
if (!op)
return;
if (cqe.flags & FI_RECV) {
op->recv.recv_size = cqe.len;
} else if (cqe.flags & FI_SEND) {
// Nothing special
} else if (cqe.flags & FI_WRITE) {
// Nothing special
} else {
fprintf(stderr, "Unhandled completion type. cqe.flags=%lx\n", cqe.flags);
std::exit(1);
}
}
if (op->callback)
op->callback(net, *op);
delete op;
}
Application Messages
First, we need to modify the AppConnectMessage to tell the server about the client’s memory region information, including the virtual address, size, and remote access key for each memory region.
struct AppConnectMessage {
struct MemoryRegion {
uint64_t addr;
uint64_t size;
uint64_t rkey;
};
AppMessageBase base;
EfaAddress client_addr;
size_t num_mr;
MemoryRegion &mr(size_t index) {
CHECK(index < num_mr);
return ((MemoryRegion *)((uintptr_t)&base + sizeof(*this)))[index];
}
size_t MessageBytes() const {
return sizeof(*this) + num_mr * sizeof(MemoryRegion);
}
};
Then we add a new message type AppRandomFillMessage to tell the server which pages on the client side should be filled with random numbers, along with page size and random seed. Additionally, the message includes a remote_context. Later, the server will send this remote_context back to the client as an immediate data so that the client can find the corresponding context.
struct AppRandomFillMessage {
AppMessageBase base;
uint32_t remote_context;
uint64_t seed;
size_t page_size;
size_t num_pages;
uint32_t &page_idx(size_t index) {
CHECK(index < num_pages);
return ((uint32_t *)((uintptr_t)&base + sizeof(*this)))[index];
}
size_t MessageBytes() const {
return sizeof(*this) + num_pages * sizeof(uint32_t);
}
};
In both of these types, we first define the fixed-length part at the beginning of the structure, and then access the variable-length part through pointers.
Server-Side Logic
Similar to the previous chapter, we’ll use a state machine to handle two different types of messages.
struct RandomFillRequestState {
Buffer *cuda_buf;
fi_addr_t client_addr = FI_ADDR_UNSPEC;
bool done = false;
AppConnectMessage *connect_msg = nullptr;
explicit RandomFillRequestState(Buffer *cuda_buf) : cuda_buf(cuda_buf) {}
void OnRecv(Network &net, RdmaOp &op) {
if (client_addr == FI_ADDR_UNSPEC) {
HandleConnect(net, op);
} else {
HandleRequest(net, op);
}
}
};
When receiving a CONNECT message, we add the client’s address to the server’s address vector and save the CONNECT message for later use.
struct RandomFillRequestState {
// ...
void HandleConnect(Network &net, RdmaOp &op) {
auto *base_msg = (AppMessageBase *)op.recv.buf->data;
CHECK(base_msg->type == AppMessageType::kConnect);
CHECK(op.recv.recv_size >= sizeof(AppConnectMessage));
auto &msg = *(AppConnectMessage *)base_msg;
CHECK(op.recv.recv_size == msg.MessageBytes());
CHECK(msg.num_mr > 0);
// Save the message. Note that we don't reuse the buffer.
connect_msg = &msg;
// Add the client to AV
client_addr = net.AddPeerAddress(msg.client_addr);
printf("Received CONNECT message from client:\n");
printf(" addr: %s\n", msg.client_addr.ToString().c_str());
for (size_t i = 0; i < msg.num_mr; i++) {
printf(" MR[%zu]: addr=0x%012lx size=%lu rkey=0x%016lx\n", i,
msg.mr(i).addr, msg.mr(i).size, msg.mr(i).rkey);
}
}
};
When receiving a RANDOM_FILL message, we first fill random numbers in the server’s own GPU buffer.
std::vector<uint8_t> RandomBytes(uint64_t seed, size_t size) { ... }
struct RandomFillRequestState {
// ...
void HandleRequest(Network &net, RdmaOp &op) {
auto *base_msg = (const AppMessageBase *)op.recv.buf->data;
CHECK(base_msg->type == AppMessageType::kRandomFill);
CHECK(op.recv.recv_size >= sizeof(AppRandomFillMessage));
auto &msg = *(AppRandomFillMessage *)base_msg;
CHECK(op.recv.recv_size == msg.MessageBytes());
printf("Received RandomFill request from client:\n");
printf(" remote_context: 0x%08x\n", msg.remote_context);
printf(" seed: 0x%016lx\n", msg.seed);
printf(" page_size: %zu\n", msg.page_size);
printf(" num_pages: %zu\n", msg.num_pages);
// Generate random data and copy to local GPU memory
printf("Generating random data");
for (size_t i = 0; i < connect_msg->num_mr; ++i) {
auto bytes = RandomBytes(msg.seed + i, msg.page_size * msg.num_pages);
CUDA_CHECK(cudaMemcpy((uint8_t *)cuda_buf->data + i * bytes.size(),
bytes.data(), bytes.size(),
cudaMemcpyHostToDevice));
printf(".");
fflush(stdout);
}
printf("\n");
// ...
}
};
Then we submit a WRITE operation for each page of data. For pages other than the last one, we skip the callback function. For the last page, we set the state machine’s done to true in the server-side callback function. We also include remote_context as an immediate data in the last page’s WRITE operation, so there will be a completion event in the client’s completion queue, and the client can find the corresponding context based on this immediate data.
struct RandomFillRequestState {
void HandleRequest(Network &net, RdmaOp &op) {
// ...
// RDMA WRITE the data to remote GPU.
for (size_t i = 0; i < connect_msg->num_mr; ++i) {
for (size_t j = 0; j < msg.num_pages; j++) {
uint32_t imm_data = 0;
std::function<void(Network &, RdmaOp &)> callback;
if (i + 1 == connect_msg->num_mr && j + 1 == msg.num_pages) {
// The last WRITE.
imm_data = msg.remote_context;
callback = [this](Network &net, RdmaOp &op) {
CHECK(op.type == RdmaOpType::kWrite);
done = true;
printf("Finished RDMA WRITE to the remote GPU memory.\n");
};
}
net.PostWrite(
{.buf = cuda_buf,
.offset = i * (msg.page_size * msg.num_pages) + j * msg.page_size,
.len = msg.page_size,
.imm_data = imm_data,
.dest_ptr =
connect_msg->mr(i).addr + msg.page_idx(j) * msg.page_size,
.dest_addr = client_addr,
.dest_key = connect_msg->mr(i).rkey},
std::move(callback));
}
}
}
};
After completing the above part, the remaining server-side main program logic becomes very simple:
constexpr size_t kMemoryRegionSize = 16 << 20;
int ServerMain(int argc, char **argv) {
// Open Network
struct fi_info *info = GetInfo();
auto net = Network::Open(info);
// Allocate and register message buffer
auto buf1 = Buffer::Alloc(kMessageBufferSize, kBufAlign);
net.RegisterMemory(buf1);
auto buf2 = Buffer::Alloc(kMessageBufferSize, kBufAlign);
net.RegisterMemory(buf2);
// Allocate and register CUDA memory
auto cuda_buf = Buffer::AllocCuda(kMemoryRegionSize * 2, kBufAlign);
net.RegisterMemory(cuda_buf);
printf("Registered 1 buffer on cuda:%d\n", cuda_buf.cuda_device);
// Loop forever. Accept one client at a time.
for (;;) {
printf("------\n");
// State machine
RandomFillRequestState s(&cuda_buf);
// RECV for CONNECT
net.PostRecv(buf1, [&s](Network &net, RdmaOp &op) { s.OnRecv(net, op); });
// RECV for RandomFillRequest
net.PostRecv(buf2, [&s](Network &net, RdmaOp &op) { s.OnRecv(net, op); });
// Wait for completion
while (!s.done) {
net.PollCompletion();
}
}
return 0;
}
Client-Side Logic
The client first obtains the server’s address and the size and number of pages to be written from the command-line arguments.
int ClientMain(int argc, char **argv) {
auto server_addrname = EfaAddress::Parse(argv[1]);
size_t page_size = std::stoull(argv[2]);
size_t num_pages = std::stoull(argv[3]);
size_t max_pages = kMemoryRegionSize / page_size;
CHECK(page_size * num_pages <= kMemoryRegionSize);
// ...
}
Then open the network interface, register a buffer for sending messages, and register two GPU buffers to store random numbers.
// Open Network
struct fi_info *info = GetInfo();
auto net = Network::Open(info);
auto server_addr = net.AddPeerAddress(server_addrname);
// Allocate and register message buffer
auto buf1 = Buffer::Alloc(kMessageBufferSize, kBufAlign);
net.RegisterMemory(buf1);
// Allocate and register CUDA memory
auto cuda_buf1 = Buffer::AllocCuda(kMemoryRegionSize, kBufAlign);
net.RegisterMemory(cuda_buf1);
auto cuda_buf2 = Buffer::AllocCuda(kMemoryRegionSize, kBufAlign);
net.RegisterMemory(cuda_buf2);
printf("Registered 2 buffers on cuda:%d\n", cuda_buf1.cuda_device);
Next, send a CONNECT message to the server.
// Send address and MR to server
auto &connect_msg = *(AppConnectMessage *)buf1.data;
connect_msg = {
.base = {.type = AppMessageType::kConnect},
.client_addr = net.addr,
.num_mr = 2,
};
connect_msg.mr(0) = {.addr = (uint64_t)cuda_buf1.data,
.size = kMemoryRegionSize,
.rkey = net.GetMR(cuda_buf1)->key};
connect_msg.mr(1) = {.addr = (uint64_t)cuda_buf2.data,
.size = kMemoryRegionSize,
.rkey = net.GetMR(cuda_buf2)->key};
bool connect_sent = false;
net.PostSend(
server_addr, buf1, connect_msg.MessageBytes(),
[&connect_sent](Network &net, RdmaOp &op) { connect_sent = true; });
while (!connect_sent) {
net.PollCompletion();
}
printf("Sent CONNECT message to server\n");
Before sending the RANDOM_FILL request, set up the REMOTE WRITE callback function.
// Prepare to receive the last REMOTE WRITE from server
bool last_remote_write_received = false;
uint32_t remote_write_op_id = 0x123;
net.AddRemoteWrite(remote_write_op_id,
[&last_remote_write_received](Network &net, RdmaOp &op) {
last_remote_write_received = true;
});
Then select some pages and send a RANDOM_FILL request.
// Prepare request
uint64_t req_seed = ...;
std::vector<uint32_t> page_idx = ...;
// Send message to server
auto &req_msg = *(AppRandomFillMessage *)buf1.data;
req_msg = {
.base = {.type = AppMessageType::kRandomFill},
.remote_context = remote_write_op_id,
.seed = req_seed,
.page_size = page_size,
.num_pages = num_pages,
};
for (size_t i = 0; i < num_pages; i++) {
req_msg.page_idx(i) = page_idx[i];
}
bool req_sent = false;
net.PostSend(server_addr, buf1, req_msg.MessageBytes(),
[&req_sent](Network &net, RdmaOp &op) { req_sent = true; });
while (!req_sent) {
net.PollCompletion();
}
printf("Sent RandomFillRequest to server. page_size: %zu, num_pages: %zu\n",
page_size, num_pages);
Wait for the last REMOTE WRITE operation to complete, then verify that the received data is correct.
// Wait for REMOTE WRITE from server
while (!last_remote_write_received) {
net.PollCompletion();
}
printf("Received RDMA WRITE to local GPU memory.\n");
// Verify data
auto expected1 = RandomBytes(req_seed, page_size * num_pages);
auto expected2 = RandomBytes(req_seed + 1, page_size * num_pages);
auto actual1 = std::vector<uint8_t>(page_size * num_pages);
auto actual2 = std::vector<uint8_t>(page_size * num_pages);
for (size_t i = 0; i < num_pages; i++) {
CUDA_CHECK(cudaMemcpy(actual1.data() + i * page_size,
(uint8_t *)cuda_buf1.data + page_idx[i] * page_size,
page_size, cudaMemcpyDeviceToHost));
CUDA_CHECK(cudaMemcpy(actual2.data() + i * page_size,
(uint8_t *)cuda_buf2.data + page_idx[i] * page_size,
page_size, cudaMemcpyDeviceToHost));
}
CHECK(expected1 == actual1);
CHECK(expected2 == actual2);
printf("Data is correct\n");
return 0;
Results
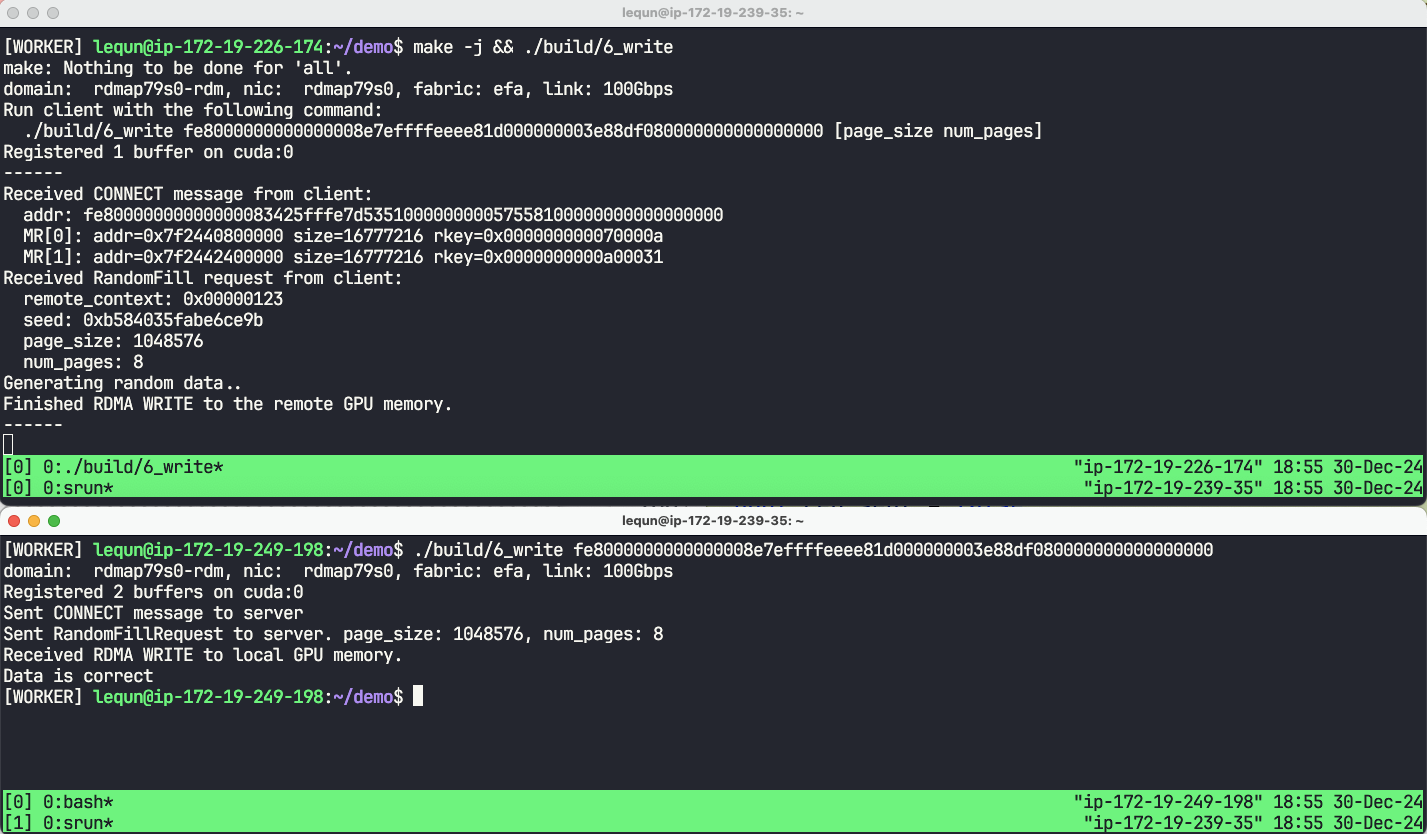
Chapter code: https://github.com/abcdabcd987/libfabric-efa-demo/blob/master/src/6_write.cpp