Harnessing 3200Gbps Network (2): High-Performance Network System Design Philosophy
Before introducing libfabric, let’s think about high-performance network library design from a higher level, which will help us understand the interfaces and programming models of both ibverbs and libfabric. On this topic, the libfabric official introduction article is very well written, and I recommend interested readers to read it carefully. In early 2021, I wrote a simple RDMA communication program using ibverbs and had many similar thoughts, so when I read this article after 3 years, it strongly resonated with me.
Sockets
First, let’s review the socket send() and recv() interfaces:
ssize_t send(int sockfd, const void* buf, size_t len, int flags);
ssize_t recv(int sockfd, void* buf, size_t len, int flags);
What applications care most about is transferring data from [buf, buf+size) to the destination represented by sockfd, and this interface is so simple it contains almost exactly that information. Since its invention in 1983, this interface has remained largely unchanged. Simplicity and generality are the secrets to its success. The interface hides all the details of the underlying network protocols, with all the dirty work encapsulated in the operating system kernel.
This interface was designed from the beginning to support both blocking and non-blocking calling modes. Switching from blocking to non-blocking mode requires just one line of code:
fcntl(sockfd, F_SETFL, O_NONBLOCK);
In blocking mode, these interface calls don’t return until some part of the message is successfully sent (or received). In non-blocking mode, these interfaces always return immediately, with the return value indicating how many bytes were sent (or received). Combined with I/O multiplexing tools like select() / poll() / epoll / io_uring, it’s easy to write network programs that can handle many requests asynchronously.
The Asynchronous Nature of Networks
Asynchronicity is the natural state of networks. Whether a network operation succeeds is far beyond the Linux kernel’s control - hardware buffers might be full requiring pauses, congestion might need control, or packet loss might require retransmission. Moreover, whether these network operations succeed cannot be known within a single function call. A packet might take hundreds of milliseconds to cross the ocean. Imagine if we were implementing the Linux kernel’s network module - how should we do it?
If the application uses blocking mode, everything is straightforward. Just wait until everything settles and then wake up the application. However, if the application uses non-blocking mode, the kernel needs to immediately return how many bytes send() successfully sent (or how many bytes recv() received). But without suspending the user-space process, the kernel might not even know if the network card has available hardware resources, let alone know how many bytes will cross the ocean in hundreds of milliseconds.
Under these constraints, one feasible implementation approach I can think of is to have the kernel maintain its own buffer. When a user-space process calls send(), the kernel copies the user’s content to its buffer. Since the kernel knows exactly how much space remains in its buffer, it can return immediately to the user-space process. Afterwards, the kernel can gradually interact asynchronously with the network from its buffer.
Obviously, in high-performance networks, we want to avoid extra copying if possible. Are there other options? For example, what if we let applications provide the buffer instead of maintaining it in the kernel? How would this idea work?
Buffer Copying
If the Linux kernel allows user-space processes to provide buffers, then the user-space process must guarantee that it won’t modify or free the buffer until the kernel notifies it that the network operation is complete. Otherwise, the transmitted data could be corrupted, the process could crash, or it could even create security vulnerabilities. This clearly conflicts with Linux’s design philosophy - the kernel shouldn’t trust user space.
I thought about this further - it’s not impossible to implement if we really wanted to. Preventing user-space processes from accessing certain memory regions isn’t particularly difficult; the kernel just needs to modify the CPU’s page tables. However, if we actually did this, it would create even more problems. For example, manipulating page tables would require buffer alignment to page size. Additionally, manipulating page tables isn’t a particularly fast operation. Frequent modifications to page tables and page table caches would also reduce execution efficiency.
In short, I think having the kernel completely trust buffers provided by user-space processes isn’t very feasible. Having the kernel maintain its own buffer is much easier, even if it requires an extra copy.
Therefore, I believe this extra copy is an inevitable consequence of the socket interface design. This additional copy and the socket’s simple, user-friendly design philosophy are two sides of the same coin.
Address Resolution
The libfabric introduction article mentions something I hadn’t thought about before - address resolution. The socket receives an IP address, but to communicate, the kernel needs to look up the lower-level address, which is the MAC address. This address resolution step also takes time. For TCP, the lower-level address can be cached when establishing the connection, so the impact is minimal. However, for UDP, because it’s connectionless, each send and receive operation needs to go through address translation, taking considerable time.
High-Performance Networks
So what kind of coordinated cooperation between applications, network interfaces, operating systems, and hardware is needed to implement high-performance networks?
Buffer Ownership
As mentioned earlier, letting applications provide buffers can avoid extra copying, but this requires applications not to read or write these buffers until network operations complete. This software-level contract, in terms of the now-fashionable Rust language, is an ownership issue. After calling a network operation, buffer ownership should transfer from the application to the network interface.
This high level of trust in user space is certainly not acceptable to the Linux kernel. But do we always need the kernel’s approval? Can user-space processes directly manipulate network cards? Is there an elegant way to ensure system security while achieving this contract?
Bypassing the Operating System Kernel
Sockets must go through the operating system kernel because only the kernel can manipulate network cards, and the entire network stack is implemented in the kernel. However, if we reverse this and implement the network stack together with user space and network cards, network calls don’t necessarily need to go through the kernel. If data doesn’t need to pass through the kernel, performance will certainly increase significantly because switching between user mode and kernel mode is very time-consuming.
Application and Network Card Shared Memory
If the operating system kernel allows applications and network cards to share certain memory spaces, all data operations can become very fast. When sending data, network cards can read directly from memory; when receiving data, network cards can write directly to memory; applications can poll the network card’s Completion Queue to know if network operations are complete, and this polling operation is just reading from a virtual address.
Control Plane and Data Plane Separation
While all this sounds good, if everything bypasses the operating system kernel and gives user space complete access to hardware, the operating system’s abstraction would be broken, and security would be compromised. In reality, we can divide network operations into two categories:
- Control Plane:
- Control plane network operations can go through the operating system kernel, with the kernel executing privileged operations to ensure system security. This is a slow path.
- Examples: enabling listening state, address resolution, registering buffers, registering completion queues
- Data Plane:
- Data plane network operations should bypass the operating system kernel, this is a fast path.
- Examples: receiving data, sending data, polling completion queues
Since we want applications to provide buffers, we can require applications to tell the operating system kernel which virtual address segment beforehand. The kernel can then make appropriate marks in the CPU’s page table. At the same time, the kernel can also set up the network card’s page table. This way, both user-space processes and network card hardware can access the same memory segment, and the kernel has preset access permissions for both parties.
If an application doesn’t follow the ownership contract, the damage is limited to crashing the application itself, cannot spread beyond user space, and won’t affect other processes in the system.
Reception Before Transmission
Without the kernel providing buffers, how does the network card know which address in the application’s memory to write to when it receives a message?
To solve this problem, we can require applications to submit several receive operations first. When new data arrives, the network card can write the data to the memory specified by one of these pending receive operations. If there are no pending receive operations when new data arrives, the network card can simply reject the data. Conversely, if an application wants to continue receiving more data, it’s the application’s responsibility to submit another receive operation after a receive operation completes.
TCP and RDMA Comparison
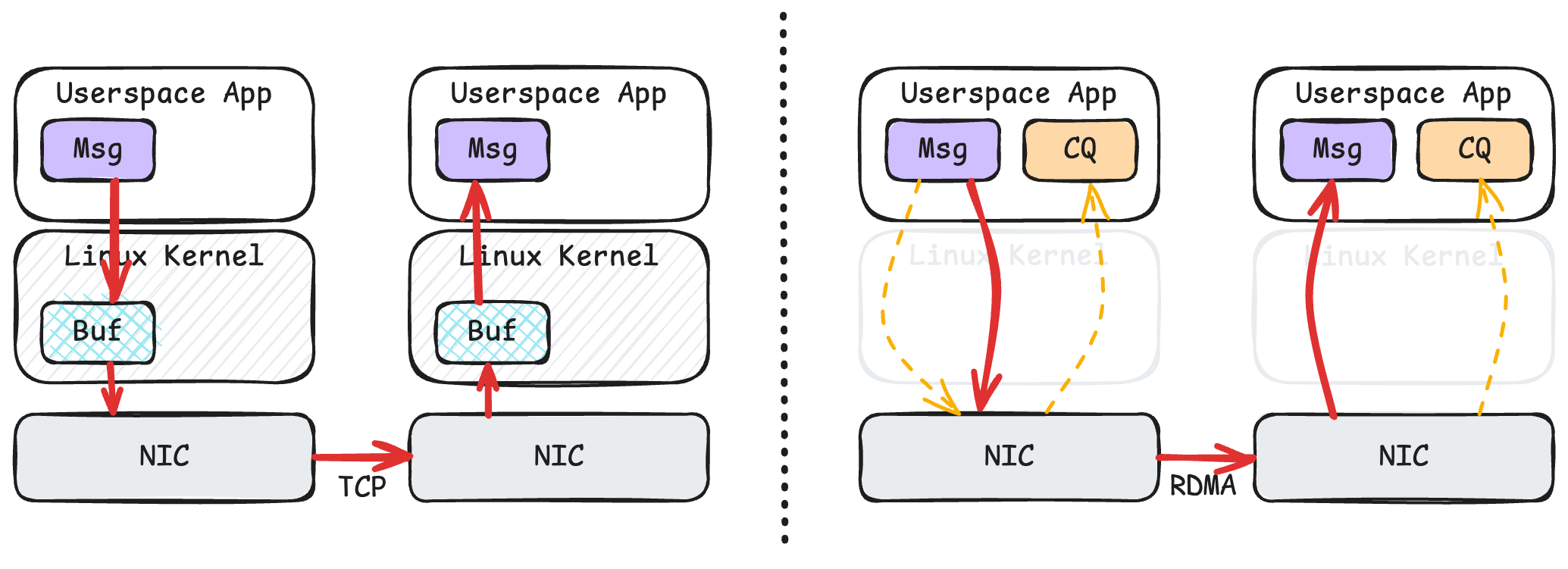
The above diagram simply illustrates the data transmission flow of TCP and RDMA.
On the left is TCP. Messages must first be copied from user space to kernel space before the kernel can drive the network card to send the message. At the receiving end, the network card writes data to the kernel, and the kernel then copies the data to user space. Due to kernel involvement and additional buffer copying, TCP’s process has relatively low performance.
On the right is RDMA. User space can directly tell the network card the memory address of the message to send, and the network card can directly read this data and send it to the remote end. Meanwhile, the user-space program can read the completion queue to know if the send operation is complete. After the operation completes, the application can reuse this memory segment. At the receiving end, the network card directly writes data to the memory region specified by the pending receive operation, then updates the completion queue. When the receiving application’s program reads the completion queue, it knows the data has arrived. RDMA’s process is undoubtedly highly efficient.
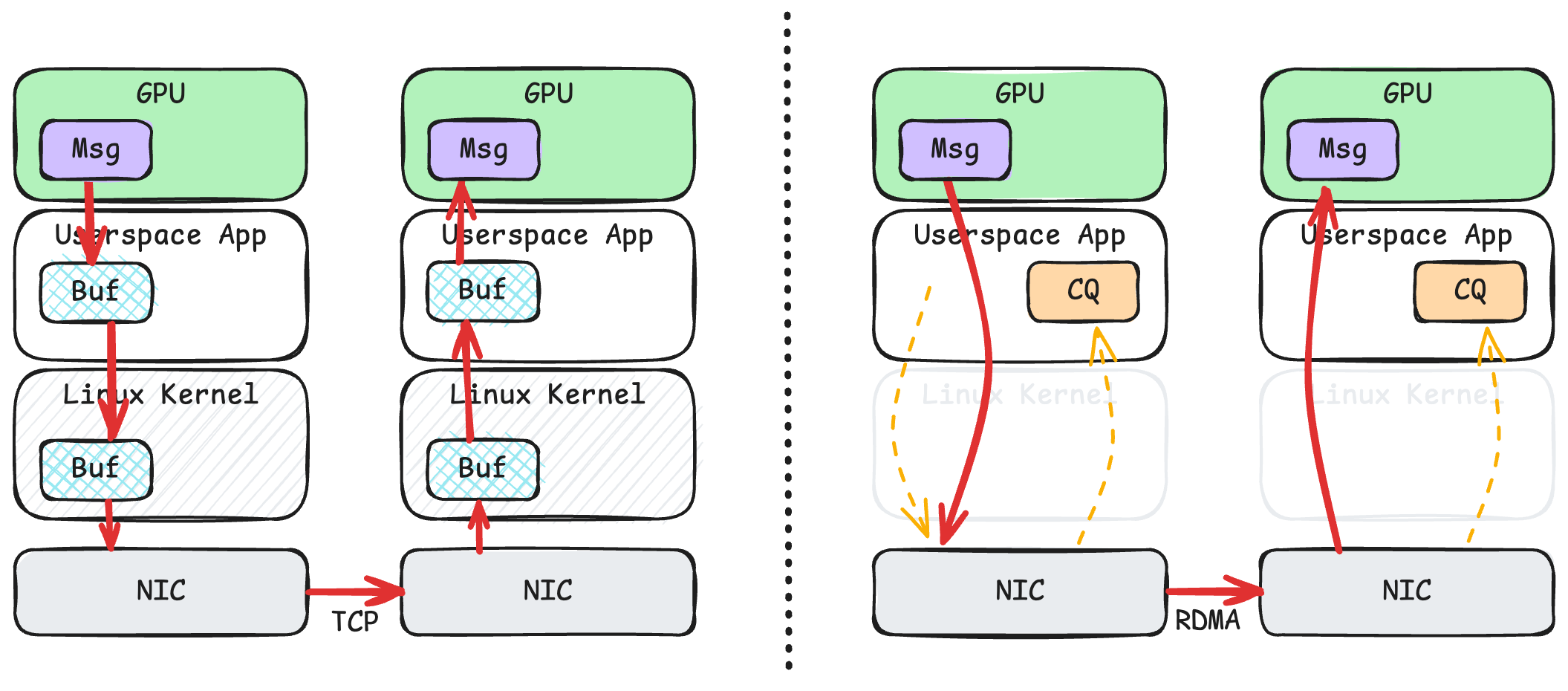
When considering GPUs, the performance difference between TCP and RDMA becomes even greater. The above diagram shows message transmission from a local GPU to a remote GPU.
On the left is TCP. Because the operating system can’t directly read GPU memory, there’s an extra copy step from GPU memory to user-space memory. Similarly at the receiving end, there’s an extra copy from user-space memory to GPU memory. This makes TCP’s already low performance even worse.
On the right is RDMA. When an application needs to send data, the user-space process only needs to tell the network card the virtual address where this message is located, and the network card can directly read from GPU memory. This technology is called GPUDirect RDMA. Notably, when sending messages, the user-space process doesn’t need to explicitly distinguish whether this virtual address is in CPU memory or GPU memory, because the kernel has preset the page tables for the CPU, GPU, and network card, allowing them to understand the same virtual address space. The receiving end is similar - the network card writes data directly to GPU memory without any extra copying.
Hardware Bus Topology
In the examples above, we can see that RDMA not only saves software overhead but also reduces data transmission on PCIe buses and memory buses. When a machine has more GPUs and network cards, we need to consider the hardware bus topology to avoid unnecessary cross-bus data transmission and bus congestion.
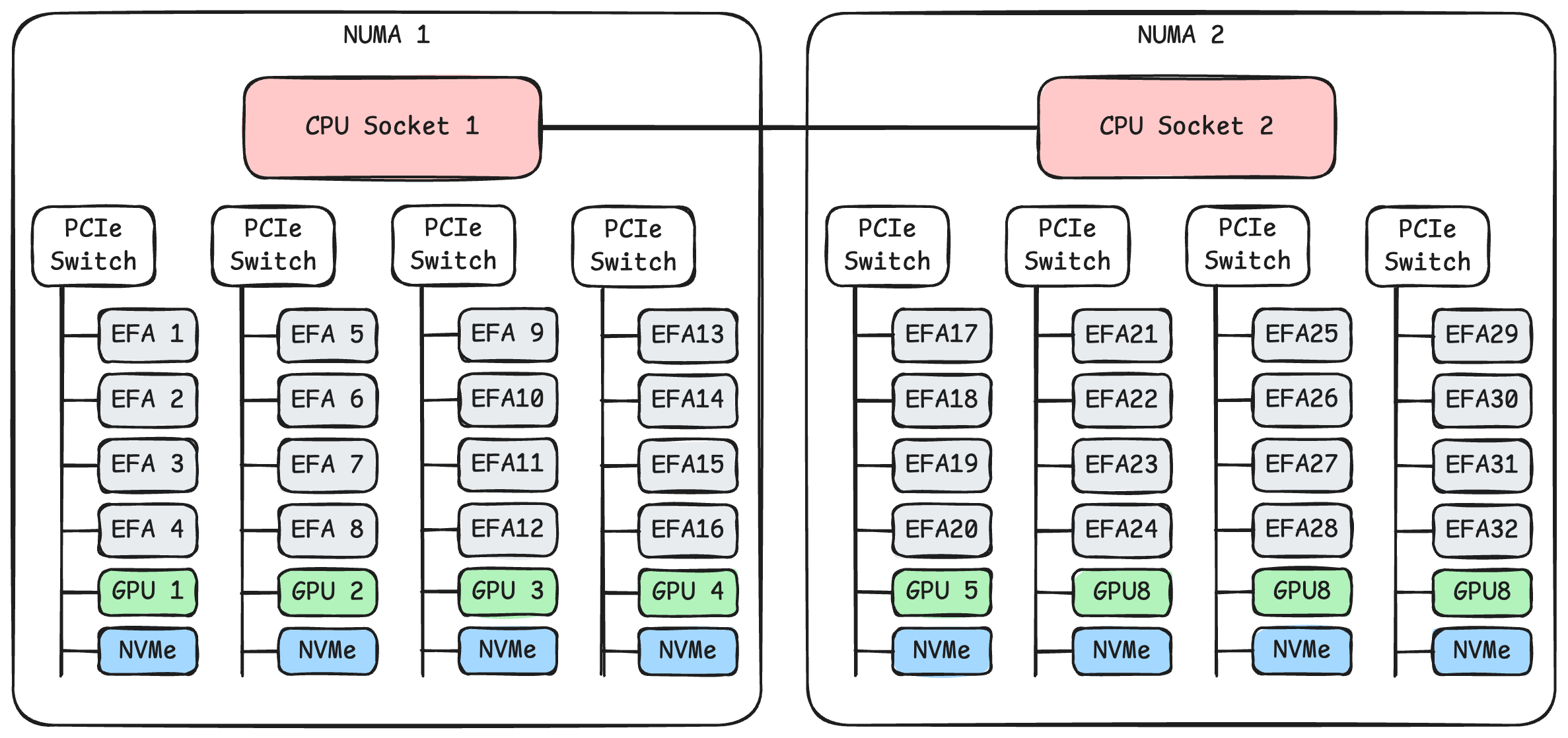
Taking AWS p5 instances as an example, the diagram above shows the system’s topology. Each machine has two CPUs. Each CPU connects to four PCIe switches. Each PCIe switch connects to four 100 Gbps EFA network cards, one NVIDIA H100 GPU, and one 3.84 TB NVMe SSD.
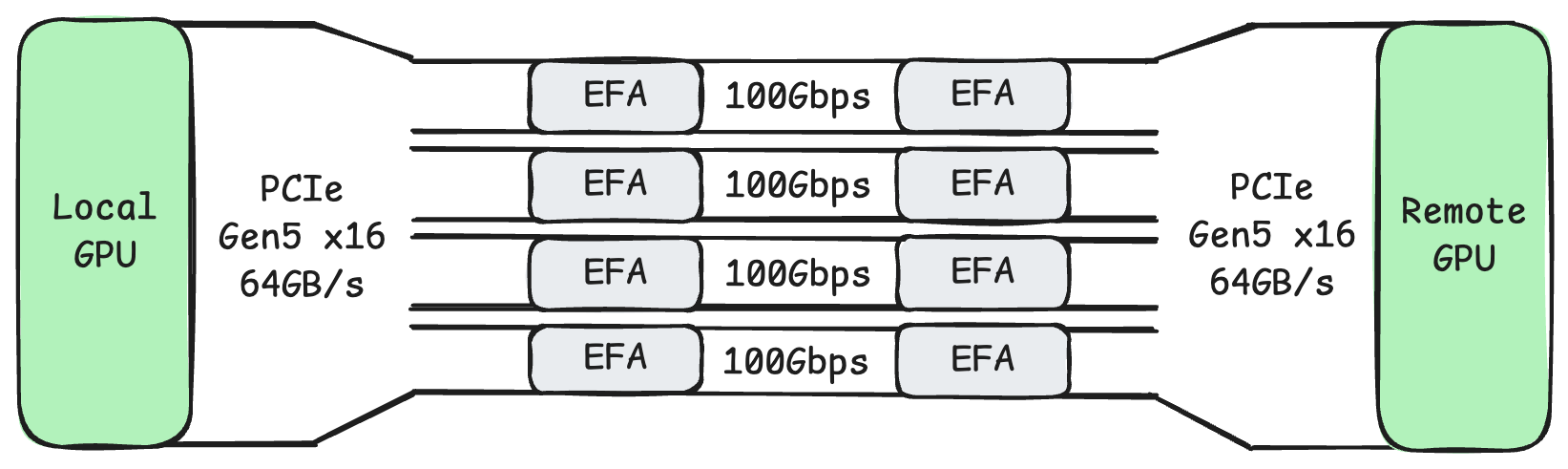
As shown above, if we pair GPUs and network cards under the same PCIe switch, then with GPUDirect RDMA, their communication only needs to go through this PCIe switch, fully utilizing PCIe Gen5 x16 bandwidth. At the same time, they won’t affect other PCIe switches or the CPU memory bus.
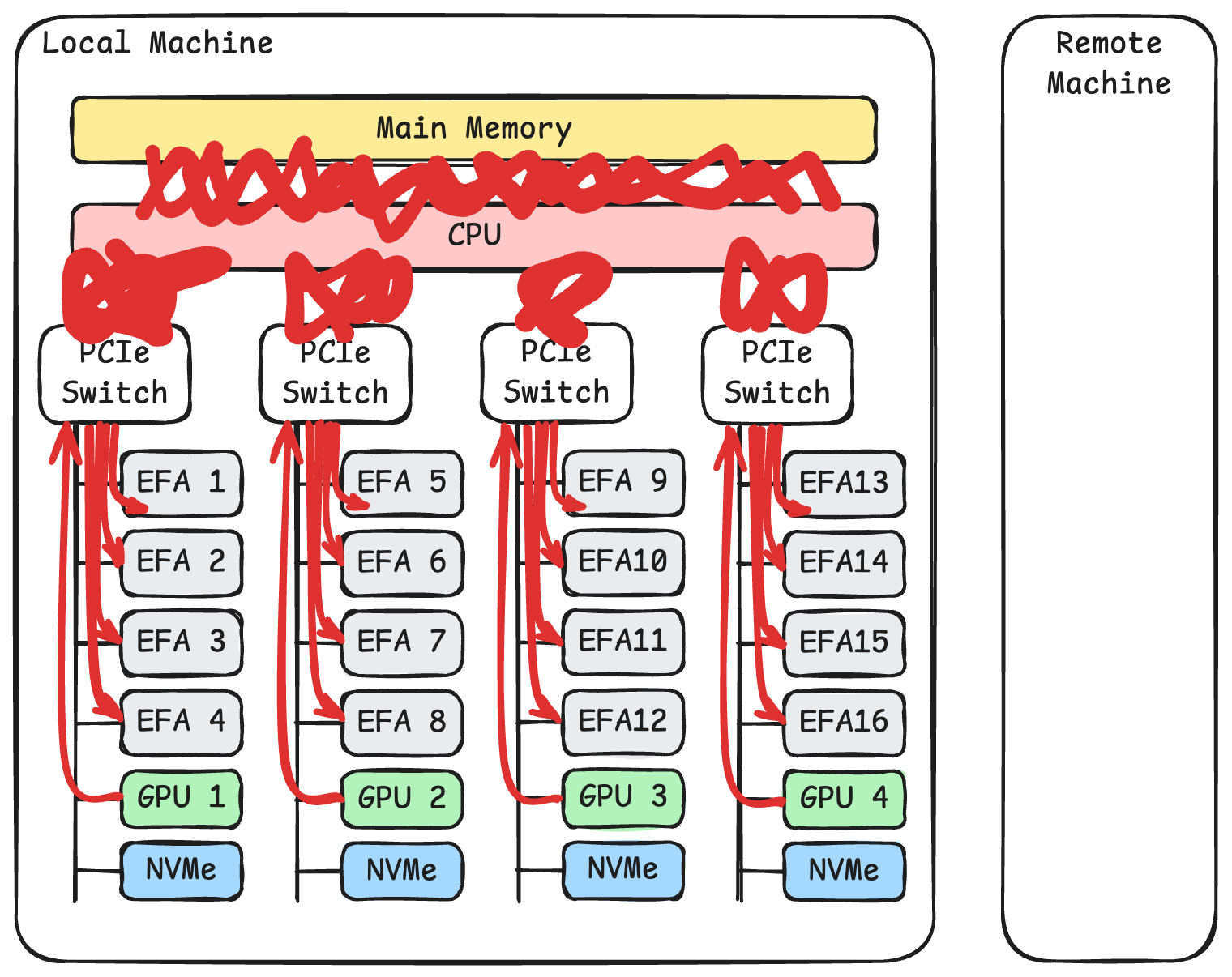
However, if using TCP for transmission, as shown above, communication between network cards and GPUs needs to take a long route. Data must travel from GPU memory through the PCIe switch, through the CPU’s internal PCIe channels, through the CPU’s memory bus, before being copied to user-space memory. Then the kernel makes another copy of this data. The kernel’s data must then travel through the CPU memory bus, through the CPU’s internal PCIe channels, through the PCIe switch, before finally reaching the network card. When 8 GPUs and 32 network cards are working simultaneously, TCP transmission like this obviously causes severe congestion on PCIe buses and memory buses.